
ctlr+r #03: OSS fatigue & Orchestrating LLMs

A weekly recall from the terminal of my mind: Thoughts 🧠, 🛠 Tools, and 📕 Takes.
🧠 Open Source projects are becoming less convincing
The business models and sustainability of open source have always been challenging.
In the past, if you wanted to push something into the open for others to use and contribute to, the bar was incredibly high. You basically had to sacrifice your evenings and weekends just to write the code. That effort was a signal: it showed a genuine commitment to, at the very least, maintain and move the project forward.
Now, with AI, anyone can spin up an open source project in a few minutes, throwing together code they’ve likely never reviewed. As a result, the commitment to maintainability has plummeted.
So, I’m looking at new open source projects with much more skepticism now—unless they are actually backed by a company.
There are still great new OSS projects, like Ghostty or Omarchy, but these are exceptions led by people who don’t need the money.
🛠 Modern orchestration for LLM workflows
As a data engineer, I’m familiar with orchestrators like Airflow, Dagster, and Kestra. These are designed for data dependencies and heavy batch compute. They are primarily declarative DAGs: “here’s the whole pipeline, go run it.”
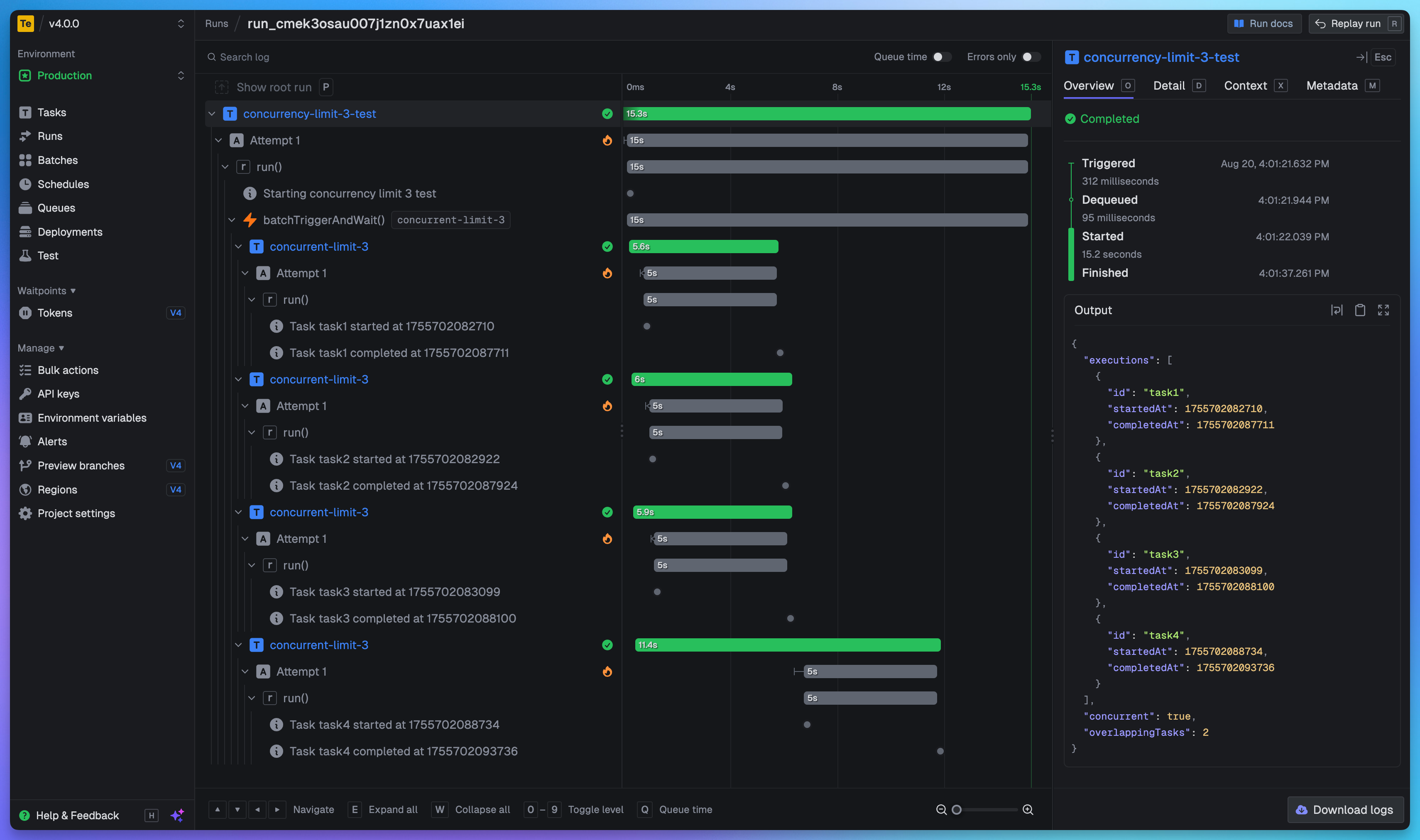
Designing LLM workflows (or agents) requires a different approach. I need dynamic execution rather than raw compute power, as the system is mostly waiting for API responses. This is where event-driven, state-machine-style orchestrators shine.
I’ve been testing trigger.dev, a lightweight serverless tool where you define tasks directly within your code. You define task within your API, and the service will call these endpoint following a specific workflow and given you clear observability. It’s nice because your orchestrations is “built-in” within your app. There’s just another service calling endpoints.
An honorable mention goes to Inngest, while Temporal offers a heavier enterprise alternative.
I’ll share a deep dive soon on these once I’ve gathered more experience.
📚 What I read / watched
650GB of Data (Delta Lake on S3): Polars vs DuckDB vs Daft vs Spark: Daniel Beach takes a “no tuning” approach, acknowledging that most devs don’t read the docs anyway. A pragmatic showdown of processing 650GB using different compute engines.
What if you don’t need MCP at all?: An interesting take suggesting we don’t always need MCP. Often, simply letting LLMs run bash scripts is enough.
Knowledge Management in the Digital Age: A hands-on look at Simon Späti ‘s “second brain.” He’s used Obsidian for years, so despite the length, there are great nuggets here for your workflow.
My biggest programming regret: A reminder to build what excites you, not just what pays. If you are passionate and get good at it, the career and money will follow naturally.
We are constantly bombarded with online success stories and “the grind.” Here’s a photo of my new daughter to remind you that success is worthless if you can’t share it with real people.
Take time with your family and friends. Life is short.
