
Data Contracts — From Zero To Hero
A pragmatic approach to data contracts

A pragmatic approach to data contracts

Recently, there has been a lot of noise around data contracts on social media. Some data practitioners shared opinions about pros and cons but mostly about what it is and its definition. While I think data contracts are a wild topic, I wanted to share my experience with pragmatic tips on how to get started. Data contracts are something real and valuable that you can start leveraging today with less effort than you think. But why do we need them in the first place?
🔥What’s the fuzz about data contracts?
Being proactive instead of reactive
If you work in data, chances are high you faced multiple times this problem: data is wrong, and you have no idea why. There seems to be a problem upstream in the data, but none of your internal colleagues knows why so what do we do? Who should we contact?
How did we end up there?
With data not being the first class citizen, data teams mostly start getting analytics on an existing infrastructure that serves other initial goals. They will “plug” their pipelines against an existing operational database, off-load data to a warehouse and handle the rest.
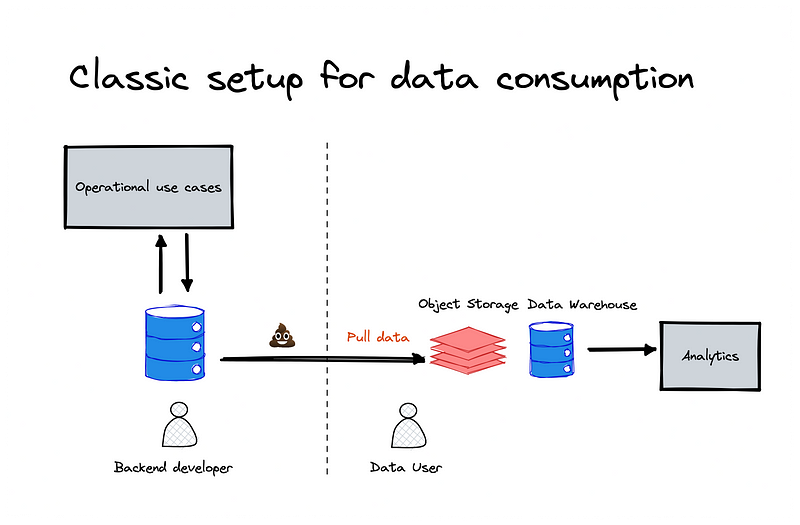
Data teams are stuck between the hammer (the operational databases they have no control) and the business screaming their needs.
They can do some magic to some extent but garbage-in garbage-out. The more problem you have upstream, the more challenging it will be for data teams.
That’s where data contracts can help. Data teams have an explicit way to ask what they need and put a more strict process to handle change management.
📎 How do we implement such contracts?
What if we could re-do everything from scratch?
It seems unrealistic at first as you rarely have the opportunity to start with a greenfield infrastructure. However, with today’s cloud technology, it’s not so far-fetched.
An event-driven architecture can help support data contracts for multiple reasons :
Events can be strongly typed, and each event can be associated with a schema version.
It’s cheap if you use a serverless event stream and the infrastructure is self-contain (per topic).
Events platforms (aka pub/sub) offer built-in connectors for classic downstream data consumption (object storage, data warehouse).
Technology like AWS Kinesis or Kafka (with managed Kafka like AWS MSK or Confluent), Cloud Pub/Sub are good options to get you started.
The idea is to create a brand new contract with the backend and agree on the best need for (data) consumers.
Backend folks often have use cases for event-driven patterns outside analytics. For instance, communicating between micro-services. Two options here :
Make compromise about the schema so that it fits both data analytics and their use case
Create an event that’s dedicated to data analytics use case
Going for 1. avoid having an explosion of events type created at the source but may be a bit hard to discuss change as more stakeholders will be involved.

Defining a process for creating/modifying a contract
Most event platforms like Kafka or AWS MSK have their schema registry (AWS Glue registry in the case of AWS). For each topic created, you will need to register a schema.
An easy way to implement such a process between data producer and data consumer is reusing a git process.

All schema creation/change/deletion can go through a git pull request. With clear ownership and consumer to a topic, you can quickly know who can approve changes to the schema. The CI/CD pipeline picks up and deploys the change with the corresponding schema on merge.
The beauty of such a process is that it forces the discussion to happen before making any change.
🚀 Production checklist
Here are a few things to recommend when implementing data contracts with an event bus.
Tip 1: Please, use typed schema
It’s a pain to maintain JSON schema. Too much freedom. A common standard for typed events is to use Avro. It’s supported by all schema registries and has a lot of interoperability with other processing engines (Flink, Spark, etc.) for further transformation.
Tip 2: Don’t go crazy on nesting fields
As we usually analyze data in a columnar format, having too many nested complex fields can be challenging for schema evolution and expensive to process. If you have a lot of nesting fields, think about splitting the event into multiples one with specific schemas.
Tip 3: BUT you can make some compromise(s) on nesting fields
If the producer is unsure about the definition of all the schema (e.g., they depend on 3rd party APIs), you can go as far as you can in the definition and leave the rest of the unknown as a JSON string. It will cost you more on the compute to explode/access such field, but it leaves more flexibility on the data producer side.
Tip 4: Set up extra metadata fields in the event.
Things like owner, domain, team_channel, or identifying PII columns with specific fields will be helpful later for clear ownership, lineage, and access management.
Schemata is a good resource to use or get inspiration about schema event modeling.
Tip 5: Don’t change a data type on a given field.
It’s better to rename a field with a new type. While we can have a mechanism downstream to detect schema version, allowing a type change on a field without renaming it will always cause a headache. If you accept one case, you will have to handle all others. So if changing an intto a stringis not hurtful; what happens when you change a intto floator a floatto int?
Tip 6: You can still implement data contracts without an event bus
If you have a place in git where you keep all DDL statements for your operational database, you can still implement most of the above. For instance, on any change done on the database, there’s a git process that alerts the consumer who will need to approve. However, it’s a bit hard as you put a contract on something already existing where the data team didn’t have the opportunity to speak up when the schema was created.
🪃 Give back ownership to the data producer
Data contracts are just a trend to give back ownership to data producers rather than having data teams suffer from whatever data we throw at them.
And this is great; it makes life easier for everything downstream and avoids silos between products and data.
The biggest challenge is organizational. Data teams must cross the barrier and talk with the backend about new processes, which can be scary. Highlighting the current pain points and bringing visibility into how the data is consumed helps to drive the discussion.
For the tooling itself, things can be set up progressively using a event platform pub/sub service, a schema registry, and git for the data contracts process.
Find a suitable project sponsor within your company and implement the pipeline from end to end. There’s no need for big bang migration; start with a small event and extend the pattern next!
📚Further reading
Implementing Data Contracts: 7 Key Learnings by Barr Moses
The Rise Of Data Contracts by Chad Sanderson
Mehdi OUAZZA aka mehdio 🧢
Thanks for reading! 🤗 🙌 If you enjoyed this, follow me on 🎥 Youtube, 🔗LinkedIn for more data/code content!
Support my writing ✍️ by joining Medium through this link