
Local LLMs, 0 cloud cost : is WebGPU key for next-gen browser AI app?
Understand WebGPU through a real-world AI demo with code, and understand the technology powering browser compute


For April Fools’ Day, I built an AI app QuackToSQL — just quack into your mic, and it instantly transcribe the "quack" and generates SQL. Who needs to type prompts anymore, right?
The beauty of this app? It starts by downloading the model directly into your browser, and after that, everything happens locally. Real-time speech-to-text powered by your browser, leveraging your local GPU. No server-side processing needed.
This black magic is possible thanks to WebGPU.
WebGPU also enables impressive graphical demos like this Ocean simulation to run entirely processed in your browser:

In this blog post, we'll explore where WebGPU came from, dive into the technical aspects of the 'QuackToSQL' project (source code available here ), and revisit what WebGPU is, and the significant opportunities it presents, especially for LLMs and leveraging local compute power.
By the end of this blog, you’ll get a feel for the power of WebGPU—and how libraries like transformers.js let you run powerful AI models efficiently, right in your users’ browsers.
Yes, you might save some money among the way, with less cloud computing and more local muscle.
Bringing graphics to the web
To understand the story behind WebGPU, we need to go down memory lane to the world of game development in the 90s.
The gaming industry was gaining momentum, and developers wanted to tap into the full potential of graphics hardware. Before widespread GPU acceleration APIs, graphics capabilities were limited, primarily because developers had to write very specific code for different graphics cards, and CPU processing was often a major bottleneck for complex scenes.
Two major developments occurred:
In 1992, Silicon Graphics introduced OpenGL (Open Graphics Library), providing a standardized way to harness the power of GPUs across different hardware.
Microsoft followed suit with DirectX for Windows, and the two became dominant graphics APIs, primarily for PC and console game development.
As the web grew, the need for a web-based graphics solution emerged. In 2011, the Khronos Group—the consortium then responsible for OpenGL—released WebGL (Web Graphics Library). WebGL allowed JavaScript to communicate with the computer's GPU directly from the browser, enabling 3D graphics on web pages without plugins.
However, WebGL's architecture, based on the older OpenGL ES 2.0 standard, faced limitations when trying to fully leverage modern graphics hardware. This was primarily because its design wasn't optimized for modern multi-core CPUs and advanced GPU features like parallel command submission.
WebGPU : graphics + compute
WebGL also lacked dedicated support for general-purpose computations on the GPU, which limited its use primarily to graphics rendering. So yes, we could get amazing games and visualizations running directly in our browsers by leveraging our GPUs—but that was about it.
WebGPU is much more than that. It supports both graphics rendering and general-purpose compute workloads (GPGPU). And with the current AI boom, I probably don't need to emphasize the importance of GPUs for general-purpose computation.
WebGPU officially reached a stable release point around April 2023 after collaboration between major players like Google, Mozilla, Apple, Intel, and Microsoft.
WebGPU aims to bring modern, low-level GPU access to web applications. It's designed based on the concepts of newer native APIs like Vulkan, Metal, and DirectX 12.
But why does this matter in the end in the context of LLMs? Anyone can run a Python script locally or use tools like Ollama to run AI models leveraging their GPU, right?
Well, not quite so easily across the board.
Making GPU computing accessible to everyone
GPUs can be tricky beasts. Native GPU programming often involves dealing with platform-specific APIs and drivers. If you look at NVIDIA's ecosystem, many powerful tools and libraries rely specifically on their hardware architecture and CUDA (Compute Unified Device Architecture).
For example, code written using NVIDIA's CUDA framework will only run efficiently (or at all) on NVIDIA GPUs. If you want your application to support AMD, Intel, or Apple Silicon GPUs, you often need to write separate code paths using different technologies like ROCm (AMD), oneAPI/OpenCL (Intel), or Metal (Apple). This adds significant development complexity and maintenance overhead.
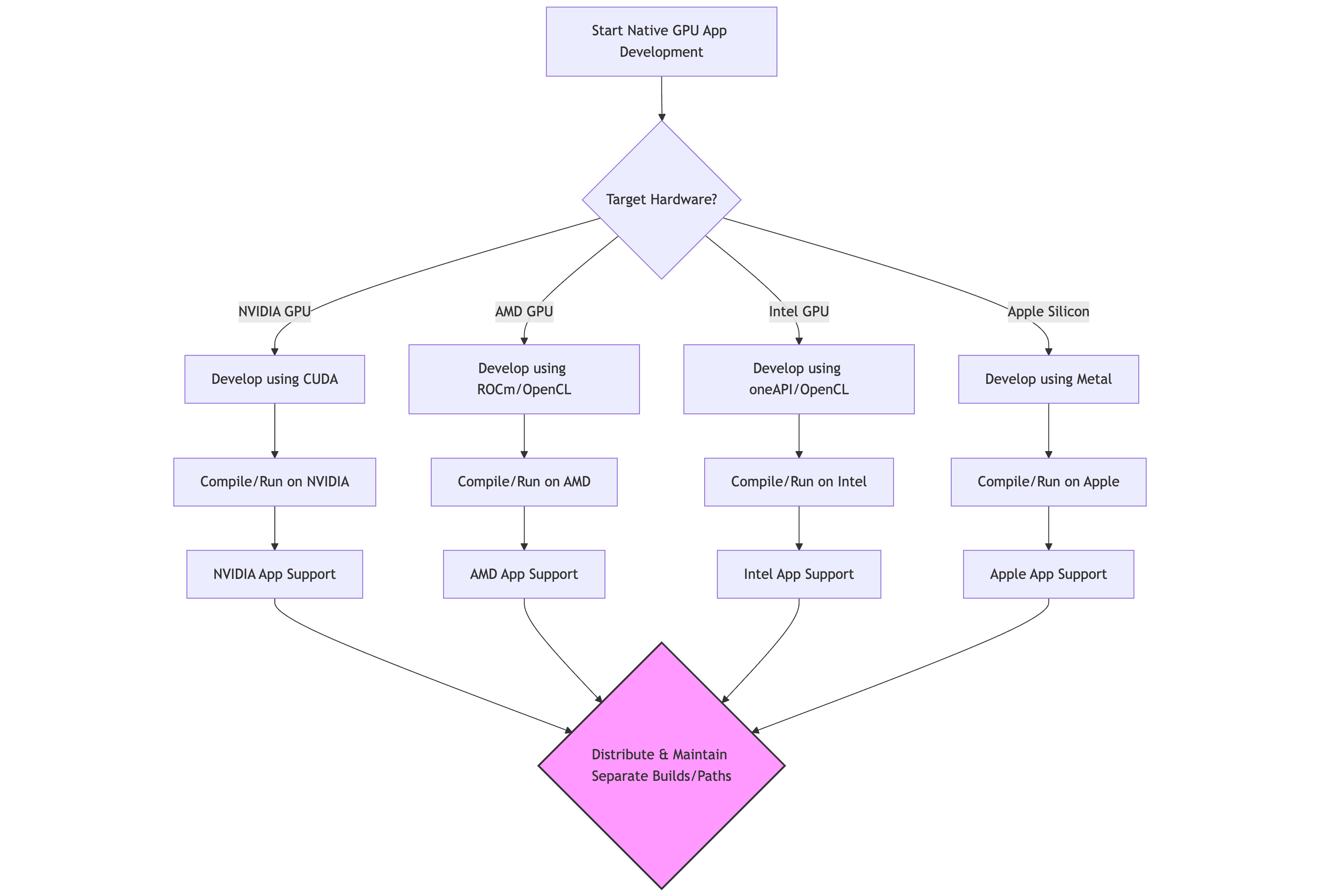
So while you can develop native AI applications targeting specific operating systems, you often end up tied to particular GPU vendor integrations or managing multiple complex build targets. On macOS, Apple Silicon provides a somewhat unified target, but across the wider PC ecosystem (Windows, Linux), the hardware landscape is diverse.
Web browser applications, using JavaScript and now WebGPU, offer a unique abstraction layer.
They make these GPU-accelerated applications potentially runnable on any device with a compatible browser, accessible via a simple URL. The browser, through its WebGPU implementation, handles the communication with the underlying native graphics drivers (Vulkan, Metal, DirectX 12).
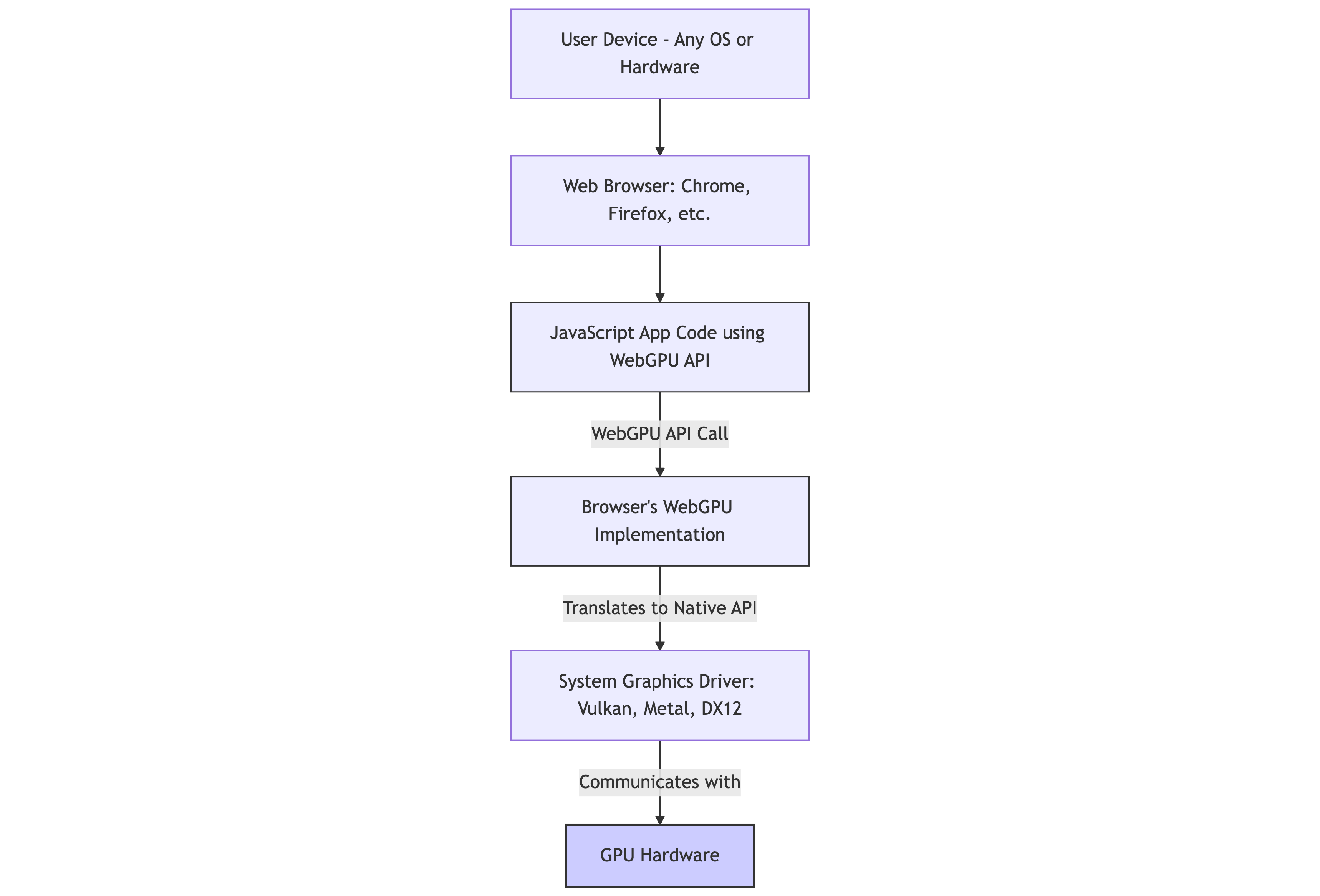
But how well is WebGPU supported?
As of early 2025, WebGPU enjoys solid support in the latest versions of Chromium-based browsers like Google Chrome and Microsoft Edge on desktop platforms (Windows, macOS, ChromeOS, Linux). Firefox support is progressing well and available, while Safari has support in Technology Previews and is expected in stable releases soon. Since many browsers build upon the Chromium project, adoption tends to propagate relatively quickly once features land there.
In short, if you're using an up-to-date version of Chrome, you're likely good to go for exploring WebGPU features.
Adding to this, we now have AI frameworks specifically designed for the web that integrate WebGPU support, all within the JavaScript ecosystem (who said Python was our only savior?!). A prime example is transformers.js.
The core transformers library is written in Python and powers most model training and inference workflows. transformers.js builds on top of it by enabling selected models to run in JavaScript—often after converting the original Python models to formats like ONNX.
Building your first AI app using WebGPU with transformers.js
For the 'QuackToSQL' April Fools' project, I needed a speech-to-text system. The goal was simple: recognize the word 'quack' in real-time and generate a random SQL query in response.
While cloud-based streaming services exist from providers like OpenAI and Google, I was skeptical about the network latency for the feedback loop I wanted. Even a one-second delay would feel sluggish for the demo, especially since I wanted a visual gauge reacting instantly to the 'quack'. I tried a couple briefly, but the latency wasn't ideal.
These cloud services are often optimized for conversational turn-taking, where studies suggest humans tolerate latencies up to a few hundred milliseconds or even close to a second before the interaction feels unnatural. However, for my use case requiring immediate visual feedback, even sub-second delays felt too long.
I needed something faster, something local.
The solution? Cut out the network round-trip entirely and process everything directly in the browser! Enter transformers.js.
As per their definition :
transformers. js is a JavaScript library for running 🤗 Transformers directly in your browser, with no need for a server! It is designed to be functionally equivalent to the original Python library, meaning you can run the same pretrained models using a very similar API
transformers.js has been around for a while. Originally developed by Joshua Lochner (Xenova), it's now officially maintained under the Hugging Face umbrella.
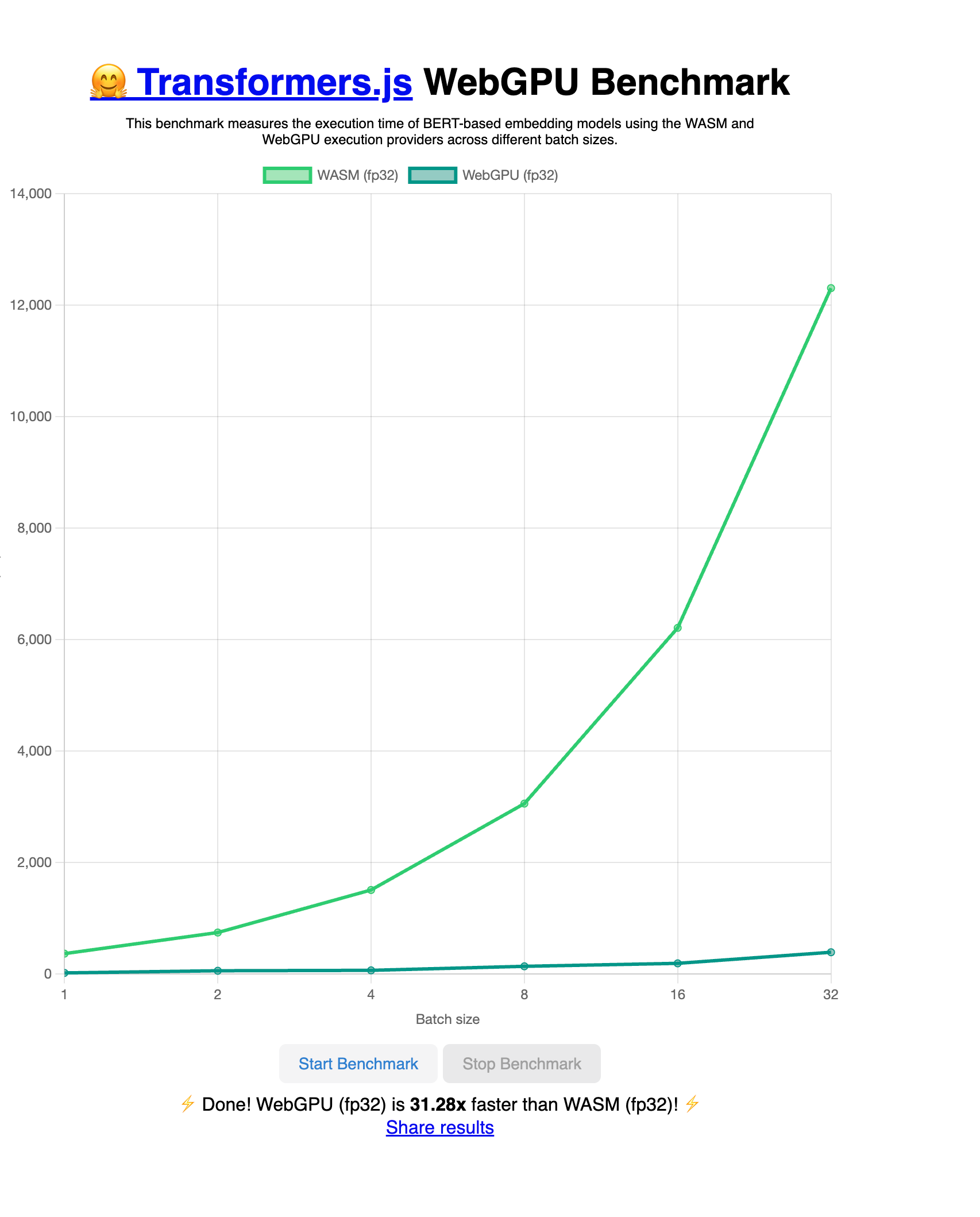
While the library existed before, robust WebGPU support was added on 3.x in late 2024, enabling significant performance improvements for model inference compared to the previous CPU/WASM backend.
Of course, performance depends heavily on your model and device but on capable GPUs, certain models and tasks have shown significant speedups—often exceeding 10×—compared to earlier WASM-based execution!
You can run the benchmark directly yourself with the Hugging Face space here
Using models in the browser
So, how do you get an AI model into the browser using this library?
Let's step back quickly about the process
When a new model architecture is released, for it to be usable in transformers.js, it typically needs to be converted and potentially added to the library's supported model list. At a high level, this often involves converting the model weights to the ONNX (Open Neural Network Exchange) format, an open standard for representing machine learning models. Depending on the complexity of the model's architecture, this conversion process might require contributions to the underlying Python Transformers library first before it can be easily exported to ONNX.
Luckily, many popular models are already converted and available directly through the Hugging Face Hub integration in transformers.js. For my project, the openai/whisper-base model was readily available and perfectly suited my need for real-time voice transcription.
A bit of Javascript on how it works
The core logic for the speech recognition in QuackToSQL resides in app/worker.ts (running in a Web Worker to avoid blocking the main UI thread). It uses the @huggingface/transformers package. Here's a simplified overview of the pipeline initialization:
class AutomaticSpeechRecognitionPipeline {
static model_id = "onnx-community/whisper-base";
static tokenizer: any = null;
static processor: any = null;
static model: any = null;
static async getInstnce(progress_callback?: (progress: any) => void) {
this.tokenizer ??= AutoTokenizer.from_pretrained(this.model_id, {
progress_callback,
});
this.processor ??= AutoProcessor.from_pretrained(this.model_id, {
progress_callback,
});
this.model ??= WhisperForConditionalGeneration.from_pretrained(
this.model_id,
{
dtype: {
encoder_model: "fp32",
decoder_model_merged: "q4",
},
device: "webgpu",
progress_callback,
},
);This code sets up the pipeline using the openai/whisper-base model. Key points:
AutoTokenizer,AutoProcessor,WhisperForConditionalGeneration: These classes handle loading the necessary components (text tokenizer, audio preprocessor, and the actual Whisper model).from_pretrained(model_id, ...): This is the core function that downloads (if needed) and loads the specified model components.dtype: { ... "q4" }: We specify using 4-bit quantization (q4) for the decoder part of the model. This significantly reduces the model size and memory usage, often with minimal impact on accuracy for this task, making it more suitable for browser environments.device: "webgpu": This crucial line tellstransformers.jsto attempt running the model inference using the WebGPU backend.progress_callback: Allows updating the UI during the potentially long model download/initialization phase.await this.model.forward(this.model.dummy_inputs);: This step uses dummy data to proactively compile WebGPU shaders and allocate resources; while not strictly necessary, it confirms the model setup and minimizes latency during the user's first interaction.
The actual transcription generation looks something like this:
async function generate({ audio, language }: GenerateParams) {
// ...
const [tokenizer, processor, model] = await AutomaticSpeechRecognitionPipeline.getInstance();
const streamer = new TextStreamer(tokenizer, {
skip_prompt: true,
skip_special_tokens: true,
callback_function,
token_callback_function,
});
const inputs = await processor(audio);
const outputs = await model.generate({
...inputs,
max_new_tokens: MAX_NEW_TOKENS,
language,
streamer,
});The audio data (likely a Float32Array) is processed.
model.generate()performs the inference using WebGPU.The
TextStreamerallows receiving transcribed text incrementally, enabling the real-time effect.
The rest of the frontend code handles audio capture from the microphone using the Web Audio API and updates the UI based on the streamer callbacks. You can explore the complete implementation in the project repository here.
WebGPU: a WIP standard
While building this, I encountered two main practical challenges with this setup:
Model download size: The
whisper-basemodel is roughly 200MB (even more before quantization). While cached by the browser after the first download, this initial load can be significant, especially on slower or mobile connections. Quantization helps, but larger models remain a challenge for web delivery.Browser configuration & compatibility: While WebGPU adoption is growing rapidly, it's still relatively new tech. This means some users might encounter issues or need to enable specific browser flags, especially on older browser versions or less common operating systems/driver combinations.
This compatibility aspect was the most common friction point users hit when trying the app. I quickly added instructions to help them:
This model requires WebGPU support. For the best experience:
- Use **Chrome** browser (recommended)
- Enable **"WebGPU"** flag in `chrome://flags`
- For **Linux** users: Ensure **Vulkan support** is installedThe Promise of local processing with WebGPU
I've been following WebGPU for a while, but this hands-on project clearly demonstrates that exciting architecture is getting closer to reality.
We can leverage the hardware already present in our laptops and desktops – including those expensive MacBooks and gaming PCs with capable GPUs – directly from the web.
The key benefits are clear:
Easy distribution: accessible via a URL, no complex installation.
Zero installation: runs directly in the user's browser.
Enhanced privacy/security: sensitive data (like raw audio in this case) can be processed locally without ever leaving the user's machine.
Reduced server costs: offloads computation to the client-side.
Potential for offline functionality: once models are cached, apps can work without constant connectivity.
Regardless of the evolution of specific libraries like transformers.js, WebGPU itself is a foundational technology enabling this shift towards more powerful local computation within the browser.
Imagine a future where commonly used AI models might even be bundled with browsers or efficiently cached across websites, eliminating download times entirely for many applications.
This could revolutionize what's possible on the web with AI.
📓Resources
WebGPU Specification: https://www.w3.org/TR/webgpu/
Transformers.js Documentation: https://huggingface.co/docs/transformers.js/index
Transformers.js Repository: https://github.com/huggingface/transformers.js
Xenova (Joshua Lochner) talk about transformer.js
WebGPU Samples: https://webgpu.github.io/webgpu-samples/
Can I use WebGPU?: https://caniuse.com/webgpu
QuackToSQL Project Repository: https://github.com/motherduckdb/quacktosql
Core transformer library : https://github.com/huggingface/transformers
Thanks for writing this! I think I’ll include it in one of my side projects as soon as I have time!