
The Key Feature Behind Lakehouse Data Architecture
Understanding the modern table formats and their current state

Understanding the modern table formats and their current state

Data Lakehouse is the next-gen architecture presented by Databricks paper in December 2020. Data Lake can be run with open formats like Parquet or ORC and leverage Cloud object storage but lacks rich management features from data warehouses, such as ACID transactions, data versioning, and schema enforcement. Today, we have more options than ever in terms of modern table formats. They all aim to solve these issues and power the Lakehouse architecture. Let's understand what these table formats bring to the table… 😉
Why? Is Parquet not enough? 🤔
Data Lake was offering good flexibility at the greatest cost. You can load (almost) whatever you want in your lake (video, images, JSON, CSV, etc), but the governance is lost. The most wanted feature we missed in Data Lake is ACID transaction. Let's understand this with a few examples :
Atomic: either the transaction succeeds or fails. It means any reader or writer will not see any potential partial successful transaction that would lead to data in a corrupted state.
Consistency: from a reader's point of view, if a column has unique values, this is preserved no matter which operation is done on the data source (a constraint on value). If a set of transactions has been committed: 2 readers will see the same data.
Isolation: if two concurrent transactions are updating the same source — it will be done like one after the other.
Durability: Once the transaction is committed it will remain in the system even if there's a crash right after.
This is something we used to have on a single database, but on a distributed system (in a Data Lake setup) where everything is on object storage, there's no isolation between reader and writer, they work directly on data files, and we have almost no metadata that makes sense to help us to achieve ACID transaction.
Lakehouse architecture embraces this ACID paradigm and requires a modern table format.
The top 3 modern table format 📑
You probably already guessed it, the modern table formats are heavily making use of metadata files to achieve ACID. With that in place, they enable different features like :
Time travel
Concurrency read/write
Schema evolution and schema enforcement
And of course, storage is always independent of the compute engine so that you can plug any storage model on your favorite Cloud provider. For instance: AWS S3, Azure Blog Storage, GCP Cloud Storage.
Apache Hudi
Created at Uber in 2016, Apache Hudi focuses more on the streaming process. It has built-in data streamers, and the transaction model is based on a timeline. This one contains all actions on the table at a different time instance. The timeline can provide time-travel through hoodie commit time.
➕ Different data ingestion engine supported: Spark, Flink, Hive
➕ Well suited for streaming process
➕ A lot of reading engines supported: AWS Athena, AWS Redshift, …
Apache Iceberg
Apache Iceberg started in 2017 at Netflix. The transaction model is snapshot-based. A snapshot is a complete list of files and metadata files. It also provides optimistic concurrency control. Time travel is based on snapshot id and timestamp.
➕ It has great design and abstraction that enables more potential: no dependency on Spark, multiple file formats support.
➕ It performs well at managing metadata on huge tables (e.g.: changing partition names on +10k partitions)
➕ A lot of reading engines supported: AWS Athena, AWS Redshift, Snowflake…
➖ Deletions & data mutation is still preliminary
Delta Lake
Delta Lake, open-sourced in 2019, was created by Databricks (creators of Apache Spark). It is no surprise that it's deeply integrated with Spark for reading and writing. It's now a major product from Databricks, and some part of it (like Delta Engine) is not open-sourced. Other product like the Delta sharing sounds really promising.
➕ It's backed by Databricks, which is one of the top companies in the data space at the moment
➖ Really tight to Spark (though this is going to change in 2022 according to their announced roadmap)
High-level summary 📓

What's the general interest? A look at Github 👀
As all projects are open-source, a good data source for evaluating the interest and growth is to look at Github itself.

As we can see, these table formats are still really young in the eyes of mainstream data users. Most of the traction appeared these past 2 years when the Lakehouse concept started to emerge.
Another interesting insight would be to look at the current number of commits, pull requests, and issues.
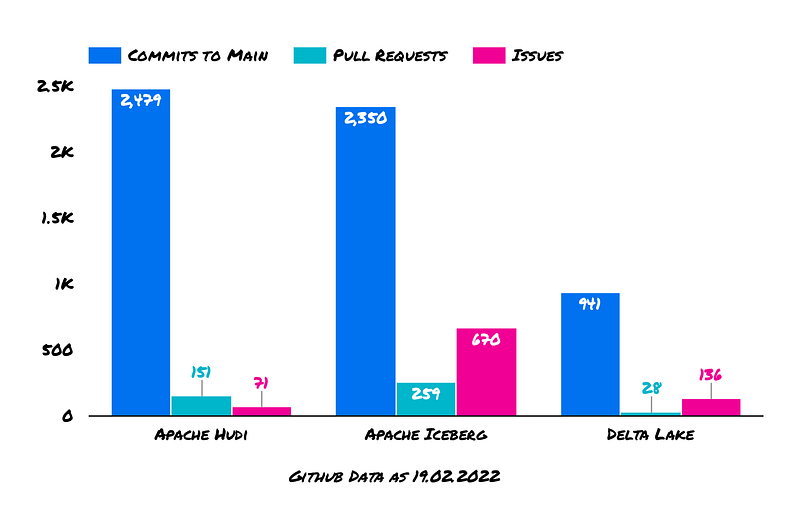
As mentioned above, some features of the Delta eco-system are not open-sourced — which explains the low number of commits compared to the traction.
Everybody wins as the future is interoperability ⚙️
No matter which format you are going to pick, and no matter who's going to win the end game, it's going in the right direction: we need more open standards in terms of data format to enable interoperability and use cases.
It's great to see general adoption on all these formats by both compute and reading engines. For instance, AWS Redshift added support for both Delta Lake and Apache Hudi in September 2020. More recently, Snowflake announced support for Apache Iceberg.
Another good thing is that all of them are backed by an open-source community. Interoperability is critical, so the more compute engines will support these formats, the less we will need to pick something that will lock us.
Mehdi OUAZZA aka mehdio 🧢
Thanks for reading! 🤗 🙌 If you enjoyed this, follow me on 🎥 Youtube, ✍️ Medium, or 🔗LinkedIn for more data/code content!
Support my writing ✍️ by joining Medium through this link